问题定位、优化
fork耗时问题? 如何解决?
在fork时子进程会拷贝父进程的页数据,所以跟服务器内存量有关,如果是虚拟化平台,特别是Xen,可能会更耗时,PS: 阿里云一部分ECS就是Xen虚拟机
root@iZ947mgy3c5Z:/prodata/scripts# dmidecode -q -t system
System Information
Manufacturer: Xen
Product Name: HVM domU
Version: 4.0.1
Serial Number: cf2cd85d-645d-4fa4-b8c1-a5eb7d822607
UUID: CF2CD85D-645D-4FA4-B8C1-A5EB7D822607
Wake-up Type: Power Switch
SKU Number: Not Specified
Family: Not Specified
System Boot Information
Status: No errors detected
解决思路:
- 避免使用Xen平台虚拟机
- 控制redis最大可用内存,fork耗时和内存容量成正比,建议10G以下 没懂啥意思?
- 调整内核参数sysctl vm.overcommit_memory=1,避免低内存情况下save失败
- 通过调整触发fork策略以降低fork频率,避免全量复制?没懂啥意思
子进程有那些开销? 如何优化?
CPU
开销分析:**
数据写入文件,属于CPU型工作?书里提到子进程负责把进程内的数据分批写到文件,这里难道不是IO密集型工作?
仔细思考了下,这里指的CPU密集可能是说将进程内的数据转为特定格式的二进制数据并写入到文件,其中设计到了大量的数据"转码(不知道这么形容对不对)",而且数据并不是一次性写入文件,而是分批写入,所以属于CPU密集
优化思路
- 避免redis进程绑定CPU,主进程会和子进程抢CPU
- 避免和其他CPU密码型进程(服务)放在一起,避免CPU争抢的问题
多实例情况下尽量保证只有一个实例在执行重写(待补充)
内存
开销分析
因为要复制父进程的内存数据,理论上需要多一倍的内存空间,但是Linux提供了写时复制,父子进程共享相同的物理空间页,父进程只需要开辟一小块内存空间用以存放被修改区域的数据
32012:C 04 Jan 13:29:29.462 * AOF rewrite: 0 MB of memory used by copy-on-write
32266:C 04 Jan 13:46:04.029 * RDB: 0 MB of memory used by copy-on-write
什么是写时复制? https://cn.wikipedia.org/zh-cn/寫入時複製
写入时复制(英语:Copy-on-write,简称COW)是一种计算机程序设计领域的优化策略。其核心思想是,如果有多个调用者(callers)同时要求相同资源(如内存或磁盘上的数据存储),他们会共同获取相同的指针指向相同的资源,直到某个调用者试图修改资源的内容时,系统才会真正复制一份专用副本(private copy)给该调用者,而其他调用者所见到的最初的资源仍然保持不变。这过程对其他的调用者都是透明的(transparently)。此作法主要的优点是如果调用者没有修改该资源,就不会有副本(private copy)被创建,因此多个调用者只是读取操作时可以共享同一份资源。
所以总的来说,开销情况如下
- RDB内存开销: COW内存开销
- AOF内存开销: COW内存开销 + aof_rewrite_buf开销
优化思路
多实例情况下尽量保证只有一个实例在执行重写(待补充)- 避免在磁盘大量写入情况下重写,因为这会导致COW大量副本,从而带来内存消耗
关闭巨页(待补充)
磁盘
开销分析
这里其实就是数据真正落地了,RDB文件应该开销较低一点,以为是二进制并且体积较小,而AOF为文本体积较大,所以开销相较于RDB会大一些
优化思路
- 不同实例数据目录设置到不同的磁盘,以分摊IO压力
- 避免和IO密集型的工作(服务)放到一起
追加阻塞问题
首先理解下流程
everysec刷盘流程
草图
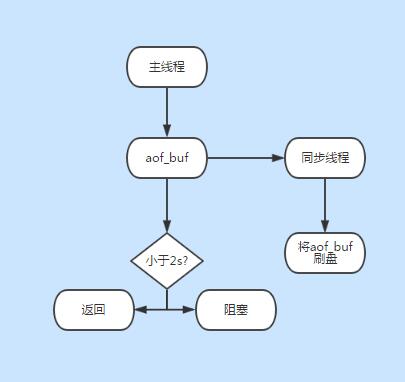
everysec丢失多少数据?
最初说是丢1s数据,但是后来又说丢2s数据,带着疑惑在源码./src/aof.c中看到,它是2秒判断的,如果小于2秒,直接return,大于两秒则开始阻塞直至同步线程完成写入,所以最大可能丢2s数据
./src/aof.c:293: } else if (server.unixtime - server.aof_flush_postponed_start < 2) {
如何定位问题是否来自aof追加阻塞?
- 日志关键字:aof fsync is talking too long(disk is busy?)
- 发生阻塞时info persistence中aof_delayed_fsync指标会累加
如何避免追加阻塞? aof最多允许两秒的阻塞,如果发生阻塞说明当前磁盘写IO性能被占用,使用iotop分析什么进程在使用IO? 将类似占用大量IO的进程迁移到其他服务器上