IP 协议
网络层(network layer)是实现全球互联网的关键。网络层有多个协议,其中最重要的是IP协议。IP协议的全称是Internet Protocol,即“互联网协议”。借着IP协议,局域网可以相互连接,最终构成覆盖全球的互联网。IP协议之外,网络层还有其他协议,如ARP、RIP和BGP。这些协议起到了辅助IP协议的作用。
IP 包格式
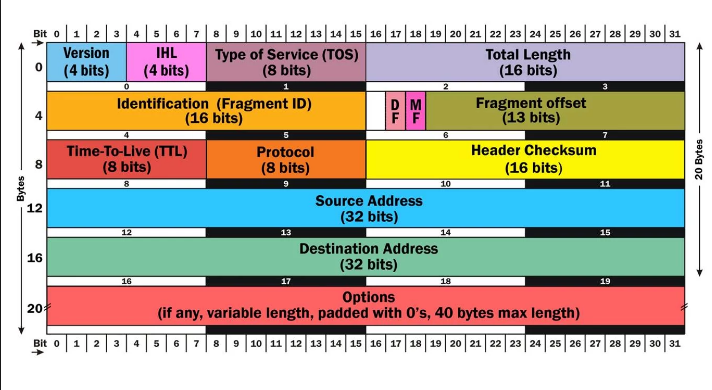
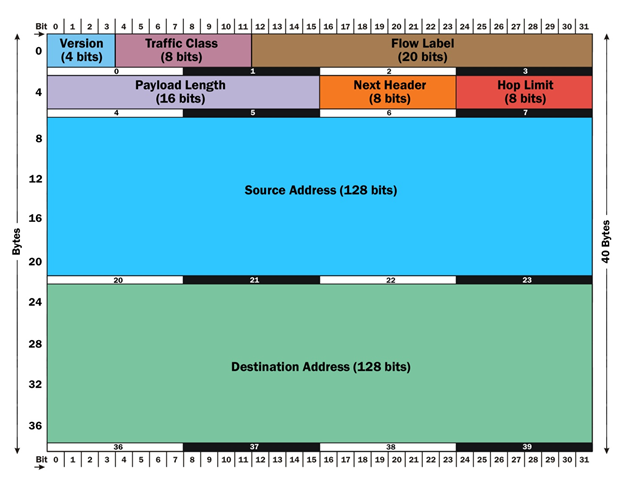
IP协议和其他网络传输协议一样,头部携带的是实现通信必须的附加信息。数据部分才是通信真正要传送的信息。IP协议规定了一个IP包头部的格式。下图是IPv4和IPv6的头部,我们来研究一下两者的异同。
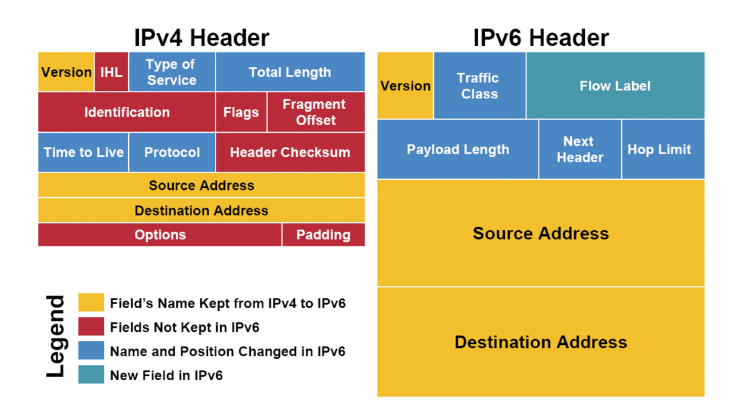
相同区域(黄)
Version
版本号(Version)占了4位的长度,用来表明IP协议版本,是IPv4还是IPv6。对于IPv4来说, 它的四位版本号是0100,即二进制的4。IPv6的四位版本号为0110,即二进制的6
Source Adrresss、Destination Address
出发地址(Source Adrresss)和目的地址(Destination Address)分别为发出地和目的地的IP地址
更名区域(蓝)
TTL(Time to Live) -> `Hop Limit
在IPv4中有存活时间(Time to Live),也就是经常看到的TTL,对应IPv6中的最大中继数(Hop Limit)。存活时间最初是表示一个IP包的最大存活时间:如果IP包在传输过程中超过存活时间,那么IP包就作废。后来,IPv4的这个区域记录一个整数。比如整数30,就表示在IP包接力过程中最多经过30个路由,如果超过30跳,那么这个IP包就作废。IP包每经过一个路由器,路由器就给存活时间减一。当一个路由器发现存活时间为0时,就不再发送该IP包。IPv6中的最大中继数记录直接就是最大路由跳数。两者不同名,但有相同功能,都避免了IP包在互联网中无限跳。
Type of Service(TOS) -> Traffic Class
原来在ipv4中服务类型(Type of Service)是用来给IP包的优先级的,例如电话通信需要比较高的实时性,所以它的优先级应该比Web服务高的,然而,这个最初不错的想法没有被微软采纳。在Windows下生成的IP包都是相同的最高优先级,所以在当时造成Linux和Windows混合网络中,Linux的IP传输会慢于Windows。说来荒唐的是,慢的原因仅仅是因为Linux更加守规矩。
后来服务类型被分为两部分
- 服务区分(
Differentiated Service Field, 即DS,前6位) 外部阻塞通知(
Explicit Congestion Notification,即ECN,后2位) 前者依然用来区分服务类型,后者用来表明IP包途径路由的交通状况在
IPv6中的交通类型(Traffic Class)其实和IPv4中的服务类型大体相似,结构上也被如此分成两部分。通过IP包提供不同服务的想法,并针对服务进行不同的优化的想法已经产生很久了,但具体做法并没有形成公认的协议。比如ECN区域,它用来表示IP包经过路径的交通状况。如果接收者收到的ECN区域显示路径上的很拥挤,那么接收者应该作出调整。但在实际上,许多接收者都会忽视ECN所包含的信息。交通状况的控制往往由更高层的比如TCP协议实现。
-------------------------2017/06/13---------------------------
看完文章后,忍不住实践了下,通过Wireshark抓包后,我看到的跟文章里学习到的名字好像有点出入
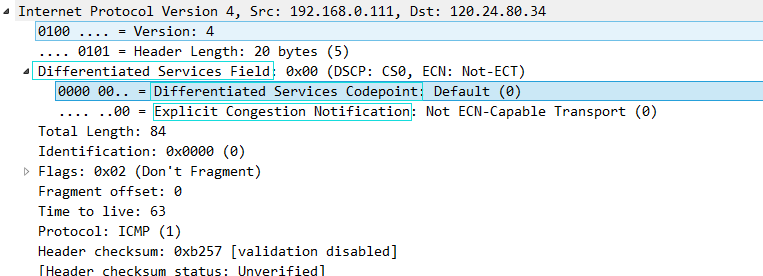 Differentiated Service Field
Differentiated Service Field
Differentiated Services CodepointExplicit Congestion Notification不过win的耍赖到时真的
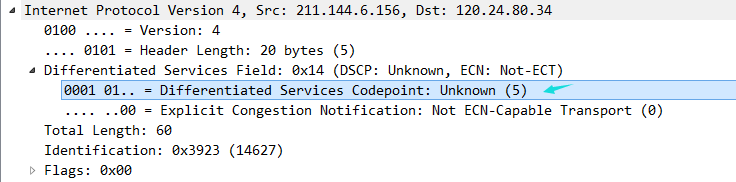
虽然不是最高级但是还是有点让人无语,同样用ping,linux老老实实的用了default 0,它却用了5,也是醉了~
Protocol -> Next Header
IPv4中的协议(Protocol),到IPv6中更名叫做内层格式(Next Header)。它们都用来说明IP包Payload部分所遵循的协议,也就是IP包的数据部分使用的更高层协议是什么。它说明了IP包封装的是一个怎样的高层协议包,比如说TCP协议或者UDP协议。
Total Length -> Payload Length
IPv4中的总长度(Total Length), 以及IPv6中数据长度(Payload Length)。它们都用来记录IP包的大小。
IPv4中的总长度是整个数据包的长度。
IPv6的数据长度只记录了数据部分的大小,但IPv6的头部是固定的长度40字节,所整个IP包的总长就是40字节加上数据长度。
删除区域(红)
Option
IPv4包在头部的最后,可以有多个选项(options)。每个选项有32位。选项不是必须的,所以一个IPv4头部可以完全没有选项。不考虑选项的话,整个IPv4头部有20字节。但由于有选项的存在,整个头部的总长度是浮动的。
IHL(Internet Header Length)
正因为上面的原因,我们用头部总长(IHL,Internet Header Length)来记录头部的总长度。通过头部总长,我们能知道哪些部分是选项。IPv6没有选项。它的头部是固定的长度40字节,所以IPv6中并不需要记录头部总长。
Header Checksum
在IPv4中有个区域是头部校验码,头部校验码(Header Checksum)区域用于校验IP包的头部信息,这里的校验码与以太网帧尾中的FCS算法不同
而IPv6没有校验相关的区域。IPv6包的校验依赖高层的协议来完成,因此免去了执行校验时间,减小了网络延迟。
Identification、flags、fragment offset
身份(Identification),标识(flags)和碎片补偿(fragment offset),这三个包都是为碎片化(fragmentation)服务的。碎片化是指一个路由器将接收到的IP包分拆成多个IP包传送,而接收这些碎片的路由器或者主机需要将碎片重新组合(reassembly)成一个IP包。不同的局域网所支持的最大传输单元(MTU, Maximum Transportation Unit)不同。如果一个IP包的大小超过了局域网支持的MTU,就需要在进入该局域网时碎片化传输。这就好像方面面面饼太大了,必须掰碎才能放进碗里。碎片化会给路由器和网络带来很大的负担。最好在IP包发出之前探测整个路径上的最小MTU,IP包的大小不超过该最小MTU,就可以避免碎片化。IPv6在设计上避免碎片化。每一个IPv6局域网的MTU都必须大于等于1280字节。IPv6的默认发送IP包大小为1280字节。
新增区域(绿)
Flow Label
流标签(Flow Label)是IPv6中新增的区域。它被用来提醒路由器来重复使用之前的接力路径。这样IP包可以自动保持出发时的顺序。这对于流媒体之类的应用有帮助。流标签的进一步应用尚在开发中。
IPv4头部信息
IPv6头部信息
IPv4说:"我尽力而为"
IP协议在产生时是一个松散的网络,这个网络由各个大学的局域网相互连接成的,由一群碰头垢面的Geek维护。所以,IP协议认为自己所处的环境是不可靠的:诸如路由器坏掉、实验室失火、某个PhD踢掉电缆之类的事情随时会发生。
这样的凶险环境下,IP协议提供的传送只能是"我尽力"(best effort)式的。所谓的"我尽力",其潜台词是,如果事情出错不要怪我,我只是答应了尽力,可没保证什么。所以,IP包传输过程中可能出现各种各样的错误,比如校验码对不上、交通太繁忙、比如超过最大存活时间,根据IP协议,你的IP包会直接被丢掉。就是这样……被丢掉了……不会再有进一步的努力来修正错误。“我尽力”原则让IP协议保持很简单的形态。更多的质量控制交给高层协议处理,IP协议只负责有效率的传输。
"效率优先"也体现在IP包的顺序上。即使出发地和目的地保持不变,IP协议也不保证IP包到达的先后顺序。我们已经知道,IP接力是根据路由表决定接力路线的。如果在连续的IP包发送过程中,路由表有时会更新,比如有一条新建的捷径出现。这种时候,后发出的IP包选择走不一样的接力路线。如果新的路径传输速度更快,那么后发出的IP包有可能先到。这就好像是多车道的公路上,每辆车都在不停变换车道,最终所有的车道都塞满汽车。这样可以让公路利用率达到最大。
IPv6中的流标签可以建议路由器将一些IP包保持一样的接力路径。但这只是"建议",路由器可能会忽略该建议。
总结
每个网络协议的形成都有其历史原因。比如IP协议是为了将各个分散的实验室网络连接起来。由于当时的网络很小,所以IPv4的地址总量为40亿。尽管当时被认为是很大的数字,但数字浪潮很快带来了地址耗尽危机。IPv6的主要目的是增加IPv4的地址容量,但同时根据IPv4的经验和新时代的技术进步进行改进,比如避免碎片化以及取消验证码。网络协议技术上并不复杂,更多的考量是政策性的。
IP协议是"我尽力"式的,IP传输是不可靠的。但这样的设计成就了IP协议的效率。